Apa itu Metode K-Nearest Neighbor (K-NN) - Data Mining (Bagian 5)
Di Googling - K-Nearest Neighbour, atau dikenal sebagai K-NN adalah algoritma pembelajaran mesin yang memiliki daftar kasus yang tersedia dan mengklasifikasikan data berdasarkan sistem pengukuran kesamaan. Model ini mengambil bagian dalam pembelajaran yang diawasi dan paling sering digunakan sebagai algoritma regresi.
Saya yakin banyak dari Anda harus berurusan dengan anak kecil, entah itu adik, sepupu, tetangga, dan masih banyak lagi. Anak-anak kecil ingin tahu tentang lingkungan mereka dan ingin tahu tentang hal-hal di sekitar mereka secara umum.
Kita dapat menganggap komputer kita sebagai anak kecil. Ia tidak tahu segalanya tetapi ingin tahu untuk belajar.
Katakanlah kita ingin mengajari komputer kita (yang seperti anak kecil), seperti apa apel itu. Kami akan menunjukkan komputer kami gambar apel, dan memberi tahu komputer, ya itu apel. Kami juga akan menunjukkan beberapa gambar buah-buahan lainnya, dan memberi tahu komputer, bukan itu bukan apel. Akhirnya, komputer akan menyadari seperti apa apel itu.

Pada dasarnya inilah cara kerja pembelajaran mesin yang diawasi. Model diberi data masukan berlabel dan harus menghasilkan keluaran yang sesuai ketika diberi data tidak berlabel.
Pengenalan Apa itu K-NN
Algoritma KNN atau K-Nearest Neighbor adalah algoritma pembelajaran mesin yang berbasis pada Supervised Learning. Artinya data yang diberikan atau masukan adalah data berlabel. Algoritma ini mengasumsikan kesamaan antara data baru dan data yang tersedia dan memasukkan kasus baru ke dalam kategori yang paling mirip dengan kategori yang tersedia.
Ini dapat digunakan untuk regresi serta untuk klasifikasi, tetapi sebagian besar digunakan untuk masalah klasifikasi. KNN adalah algoritma non parametrik yang berarti tidak membuat asumsi khusus tentang jenis fungsi pemetaan. sekumpulan parameter yang tersedia.
Cara sederhana untuk memahami adalah ketika KNN membuat prediksi untuk data baru berdasarkan pola pelatihan yang serupa dan bukan berdasarkan fungsi yang telah ditentukan sebelumnya seperti dalam kasus regresi linier di mana parameternya tetap. Satu-satunya asumsi yang dibuat tentang data adalah bahwa pola pelatihan dan data baru yang memiliki kesamaan paling banyak di antara mereka diklasifikasikan dalam kategori tertentu.
KNN juga merupakan algoritme pembelajar yang malas. Dengan algoritme pembelajar yang malas, ini berarti bahwa KNN tidak langsung belajar dari set pelatihan, melainkan menyimpan data pelatihan dan pada saat klasifikasi ia melakukan pekerjaannya pada dataset.
Mengapa kita menggunakan algoritma K-NN?
KNN dapat digunakan untuk masalah prediksi klasifikasi dan regresi. Namun lebih banyak digunakan dalam masalah klasifikasi.
Algoritma KNN dapat bersaing dengan model yang paling akurat karena membuat prediksi yang sangat akurat. Oleh karena itu, Anda dapat menggunakan algoritme KNN untuk aplikasi yang memerlukan akurasi tinggi tetapi tidak memerlukan model yang dapat dibaca manusia.
Manfaat K-NN dibandingkan algoritma lain?
- Tidak Ada Periode Pelatihan: KNN disebut Lazy Learner (Instance based learning) . Itu tidak belajar apa-apa dalam periode pelatihan. Itu tidak mendapatkan fungsi diskriminatif apa pun dari data pelatihan. Dengan kata lain, tidak ada periode pelatihan untuk itu. Ini menyimpan dataset pelatihan dan belajar darinya hanya pada saat membuat prediksi waktu nyata. Ini membuat algoritma KNN jauh lebih cepat daripada algoritma lain yang membutuhkan pelatihan misalnya SVM, Regresi Linear dll.
- Karena algoritme KNN tidak memerlukan pelatihan sebelum membuat prediksi, data baru dapat ditambahkan dengan mulus yang tidak akan memengaruhi keakuratan algoritme.
- KNN sangat mudah diimplementasikan . Hanya ada dua parameter yang diperlukan untuk mengimplementasikan KNN yaitu nilai K dan fungsi jarak (misalnya Euclidean atau Manhattan dll.
Kapan kita menggunakan algoritma K-NN?
Ini adalah algoritma non-parametrik , artinya tidak membuat asumsi apa pun pada distribusi data yang mendasarinya. Dengan kata lain, struktur model ditentukan dari data. Jika Anda memikirkannya, ini sangat berguna, karena di "dunia nyata", sebagian besar data tidak mematuhi asumsi teoretis yang dibuat (seperti dalam model regresi linier, misalnya).
Oleh karena itu, KNN dapat dan mungkin harus menjadi salah satu pilihan pertama untuk studi klasifikasi ketika hanya ada sedikit atau tidak ada pengetahuan sebelumnya tentang data distribusi.
Bagaimana cara kerja algoritma K-NN?
Algoritma KNN menghitung probabilitas data uji yang termasuk dalam kelas data latih 'K' dan kelas yang memiliki probabilitas tertinggi akan dipilih. Dalam kasus regresi, nilainya adalah rata-rata dari titik pelatihan yang dipilih 'K'.
Mari lihat contoh di bawah ini untuk membuatnya pemahaman yang lebih baik

Misalnya, kita memiliki gambar makhluk yang mirip dengan kucing dan anjing, tetapi kita ingin mengetahui apakah itu kucing atau anjing. Jadi untuk identifikasi ini, kita bisa menggunakan algoritma KNN, karena bekerja pada ukuran kesamaan. Model KNN kami akan menemukan fitur serupa dari kumpulan data baru ke gambar kucing dan anjing dan berdasarkan fitur yang paling mirip akan memasukkannya ke dalam kategori kucing atau anjing.

Mengapa kita membutuhkan Algoritma K-NN?
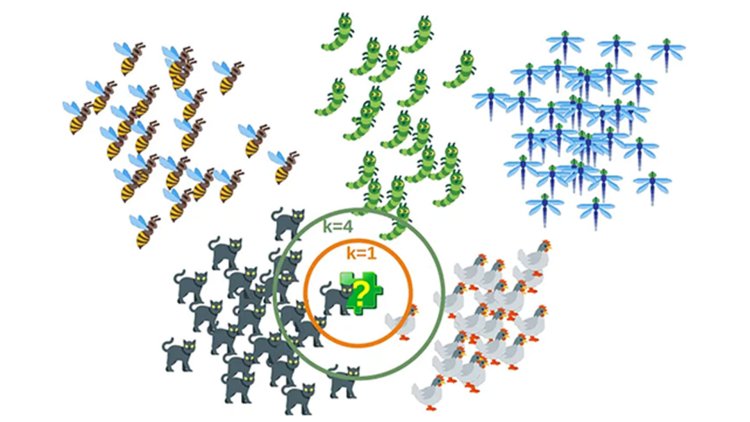
Misalkan ada dua kategori, yaitu Kategori A dan Kategori B, dan kita memiliki titik data baru x1, maka titik data ini akan terletak pada kategori yang mana. Untuk mengatasi jenis masalah ini, kita membutuhkan algoritma K-NN. Dengan bantuan K-NN, kita dapat dengan mudah mengidentifikasi kategori atau kelas dari dataset tertentu. Pertimbangkan diagram di bawah ini:

Bagaimana cara kerja K-NN?
Kerja K-NN dapat dijelaskan berdasarkan algoritma di bawah ini:
- Langkah-1: Pilih nomor K dari tetangga
- Langkah-2: Hitung jarak Euclidean dari K jumlah tetangga
- Langkah-3: Ambil K tetangga terdekat sesuai jarak Euclidean yang dihitung.
- Langkah-4: Di antara k tetangga ini, hitung jumlah titik data di setiap kategori.
- Langkah-5: Tetapkan poin data baru ke kategori yang jumlah tetangganya maksimum.
- Langkah-6: Model kita sudah siap.
Misalkan kita memiliki titik data baru dan kita perlu memasukkannya ke dalam kategori yang diperlukan. Perhatikan gambar di bawah ini:

- Pertama, kita akan memilih jumlah tetangga, jadi kita akan memilih k=5.
- Selanjutnya, kita akan menghitung jarak Euclidean antara titik data. Jarak Euclidean adalah jarak antara dua titik, yang telah kita pelajari dalam geometri. Itu dapat dihitung sebagai:

- Dengan menghitung jarak Euclidean kita mendapatkan tetangga terdekat, sebagai tiga tetangga terdekat dalam kategori A dan dua tetangga terdekat dalam kategori B. Perhatikan gambar di bawah ini:

- Seperti yang kita lihat 3 tetangga terdekat berasal dari kategori A, maka titik data baru ini harus termasuk dalam kategori A.
Bagaimana cara memilih nilai K?
K-value menunjukkan jumlah tetangga terdekat. Kami harus menghitung jarak antara titik uji dan titik label terlatih. Memperbarui metrik jarak dengan setiap iterasi mahal secara komputasi, dan itulah mengapa KNN adalah algoritme pembelajaran yang malas.

- Seperti yang dapat Anda verifikasi dari gambar di atas, jika kami melanjutkan dengan K = 3, maka kami memperkirakan input tes milik kelas B, dan jika kami melanjutkan dengan K = 7, maka kami memprediksi bahwa input tes milik kelas A.
- Begitulah cara Anda membayangkan bahwa nilai K memiliki efek yang kuat pada kinerja KNN.
Lalu bagaimana cara memilih nilai K yang optimal?
- Tidak ada metode statistik yang ditentukan sebelumnya untuk menemukan nilai K yang paling menguntungkan.
- Inisialisasi nilai K acak dan mulai komputasi.
- Memilih nilai K yang kecil menyebabkan batas keputusan yang tidak stabil.
- Nilai K yang substansial lebih baik untuk klasifikasi karena mengarah pada kelancaran batas keputusan.
- Turunkan plot antara tingkat kesalahan dan K yang menunjukkan nilai dalam rentang yang ditentukan. Kemudian pilih nilai K yang memiliki tingkat kesalahan minimum.
Sekarang Anda akan mendapatkan ide untuk memilih nilai K optimal dengan mengimplementasikan model tersebut.
Menghitung jarak:
Langkah pertama adalah menghitung jarak antara titik baru dengan setiap titik latihan. Ada berbagai metode untuk menghitung jarak ini, di antaranya metode yang paling umum dikenal adalah: Euclidian, Manhattan (untuk kontinu) dan jarak Hamming (untuk kategorikal).
Jarak Euclidean: Jarak Euclidean dihitung sebagai akar kuadrat dari jumlah perbedaan kuadrat antara titik baru (x) dan titik yang ada (y).
Jarak Manhattan: Ini adalah jarak antara vektor nyata menggunakan jumlah perbedaan absolutnya.

Jarak Hamming: Ini digunakan untuk variabel kategori. Jika nilai (x) dan nilai (y) sama, maka jarak D akan sama dengan 0 . Jika tidak D=1.

Mari kita pertimbangkan untuk kasus sederhana dengan plot dua dimensi. Jika kita melihat secara matematis, intuisi sederhananya adalah menghitung jarak euclidean dari titik tujuan (yang kelasnya perlu kita tentukan) ke semua titik dalam set pelatihan. Kemudian kami mengambil kelas dengan poin mayoritas. Ini disebut metode brute force.
1. Pohon k-Dimensi (pohon kd)
kd tree adalah pohon biner hierarkis. Saat algoritme ini digunakan untuk klasifikasi k-NN, algoritme ini mengatur ulang seluruh dataset dalam struktur pohon biner, sehingga saat data uji disediakan, algoritme ini akan memberikan hasil dengan melintasi pohon, yang membutuhkan waktu lebih sedikit daripada pencarian kasar.

Untuk pemahaman yang lebih baik tentang bagaimana tampilannya dalam topik ilmu komputer, Anda dapat menemukan kode HTML di bawah ini. Pohon membantu menyusun situs web dan situs web biasanya dapat digambarkan menggunakan pohon.
2. Pohon Ball
Mirip dengan pohon kd, Pohon bola juga merupakan struktur data hierarkis. Ini sangat efisien khususnya dalam hal dimensi yang lebih tinggi.
- Dua cluster dibuat pada awalnya
- Semua titik data harus dimiliki setidaknya oleh salah satu cluster.
- Satu titik tidak bisa berada di kedua cluster.
- Jarak titik dihitung dari centroid masing-masing cluster. Titik yang lebih dekat ke pusat massa masuk ke dalam kluster tertentu.
- Setiap cluster kemudian dibagi menjadi sub cluster lagi, kemudian titik-titik tersebut diklasifikasikan ke dalam setiap cluster berdasarkan jarak dari centroid.
- Beginilah cara cluster disimpan untuk dibagi hingga kedalaman tertentu.

3. Ball Tree hasil akhir sebagai berikut,

Perbandingan dan Ringkasan
Brute Force mungkin merupakan metode yang paling akurat karena pertimbangan semua titik data. Oleh karena itu, tidak ada titik data yang ditetapkan ke kluster palsu. Untuk kumpulan data kecil, Brute Force dapat dibenarkan, namun untuk meningkatkan data, KD atau Ball Tree adalah alternatif yang lebih baik karena kecepatan dan efisiensinya.
Penerapan algoritma K-NN?
- Peringkat kredit - mengumpulkan karakteristik keuangan vs. membandingkan orang dengan fitur keuangan serupa ke database. Berdasarkan sifat dari peringkat kredit, orang yang memiliki detail keuangan serupa akan diberikan peringkat kredit yang serupa. Oleh karena itu, mereka ingin dapat menggunakan database yang ada untuk memprediksi peringkat kredit pelanggan baru, tanpa harus melakukan semua perhitungan.
- Haruskah bank memberikan pinjaman kepada individu? Akankah seseorang gagal membayar pinjamannya? Apakah orang itu lebih dekat sifatnya dengan orang yang gagal bayar atau tidak gagal bayar pinjamannya?
- Dalam ilmu politik — mengklasifikasikan calon pemilih ke "akan memilih" atau "tidak akan memilih", atau "memilih Demokrat" atau "memilih Republik".
- Contoh lebih lanjut dapat mencakup deteksi tulisan tangan (seperti OCR), pengenalan gambar, dan bahkan pengenalan video.
- Digunakan dalam sistem pemberi rekomendasi.
- Digunakan dalam Kategorisasi Dokumen.
Kelebihan K Tetangga Terdekat
- Algoritma sederhana dan karenanya mudah untuk menginterpretasikan prediksi
- Non parametrik, jadi tidak membuat asumsi tentang pola data yang mendasarinya
digunakan untuk klasifikasi dan Regresi - Langkah pelatihan jauh lebih cepat untuk tetangga terdekat dibandingkan dengan algoritma pembelajaran mesin lainnya
Kekurangan algoritma K-NN?
- Kebutuhan memori yang tinggi (untuk menyimpan data sekaligus) sehingga pelatihan menjadi sangat lambat.
- Mahal secara komputasi (membutuhkan lebih banyak ruang untuk menyimpan data sehingga meningkatkan kebutuhan daya komputasi).
- K-NN tidak bekerja dengan baik pada kumpulan data dengan banyak fitur (ratusan atau lebih), dan sangat buruk dengan kumpulan data yang jarang.
Demikian pembahasan mengenai Apa itu Metode K-Nearest Neighbor (K-NN) - Data Mining, dapat disimpulkan bahwa KNN adalah teknik klasifikasi yang sangat berguna dalam pembelajaran mesin dan memiliki tingkat akurasi yang sangat tinggi. Saya harap artikel ini sangat membantu anda dan terima kasih.






